Einleitung
Allgemeines
Der Weg zum
HEX-File
Die Sprache C
ein einfaches Projekt
ein umfangreiches Projekt
Bibliotheken
weiter
zu
C18
weiter zu C30
weiter zur Einführung in C für
PICs
Meine ersten Eigenbaurechner Auf Z80-Basis musste ich anfangs mangels Compiler in Maschinencode und in Assembler programmieren. Später programmierte ich auch PICs (14- und 12-Bit-Kern-PICs) in Assembler. Assemblerprogrammierung ist das genaue Gegenteil der Hochsprachenprogrammierung. Man arbeitet nur auf der Hardwareebene, hat ständig alle Finger im Getriebe des Prozessors und immer ölverschmierte Hände.
Das Programmieren in einer Hochsprache
ist zweifellos komfortabler und man kommt deutlich schneller zum
Ergebnis.
Der Nachteil der Hochsprachen ist aber der langsamere und
größere
Code, den sie erzeugen. Besonders deutlich sieht man das an modernen
PCs.
Trotz Gigaherz-Prozessoren und Gigabyte-RAM sind moderne
Windows-Programme
nicht schneller als ihre Vorgänger vor 10 Jahren auf den
damaligen, wesentlich schwächeren
Maschinen.
Im
Gegensatz zu
Assemblercode sind richtige Programmiersprachen (wie C) portabel. Das
bedeutet,
dass ein C-Programm auf völlig unterschiedlichen Prozessoren zum
Laufen
gebracht werden kann. Die entsprechende Anpassung erledigt der
Compiler. Ein Assemblerprogramm ist dagegen an eine bestimmte Hardware
(Prozessoren- oder Microcontollerfamilie) gebunden.
Die minimalistischen 12-Bit-Kern-Prozessoren sind hochsprachen-ungeeignet, und die 14-Bit-Kern-Prozessoren stellen mit ihren zerklüfteten Speicherstrukturen und den kleinen Hardware-Stacks auch nicht die ideale Basis für Hochsprachen dar. Die größeren PICs (PIC18F, PIC24F/H, dsPIC30F, dsPIC33F) haben aber ausreichend Ressourcen, um mit Hochsprachen programmiert zu werden. Für diese Typen gibt es auch C-Compiler als kostenlose Student-Edition von Microchip.
C sieht zwar aus wie eine Hochsprache,
ist aber viel maschinennäher als z.B. Pascal. Man kann zwar ein
Programm
viel schneller erstellen als in Assembler, aber man macht sich
immer
noch die Hände schmutzig. Kenntnisse über den Prozessor sind
bei der Programmierung in C sehr hilfreich.
PIC-CWer ein vergleichbares, einfach verständliches Buch in deutscher Sprache kennt, sollte mir das mitteilen. Es wäre eine echte Kaufempfehlung.
An Introduction to programming the Microchip PIC in C
Autor: Nigel Gardner
ISBN: 1-899013-04-0
Sprache: englisch
hier online zu lesen
ein
einfaches
Projekt
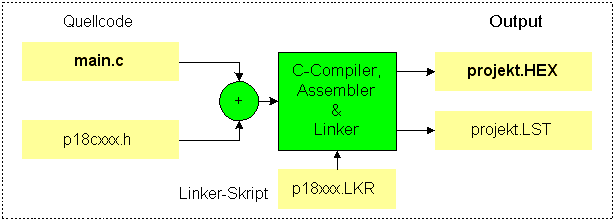
Ein kleines C-Programm schreibt man
einfach
in ein Textfile. Da es dann das einzige und damit automatisch das
Haupt-Quelltext-File
ist, bekommt es den Namen "main.c".
Im Quelltextfile main.c wird
(mit einer #include-Direktive) das sogenannte Device-Header-File (p18cxxx.h)
eingebunden.
Aus
ihm
erfährt
der C-Compiler die Namen und Typen
aller
Bezeichner, die man in Assemblerprogrammen benutzen kann (z.B. TRISA,
PORTA
u.s.w.). Mit diesem Wissen wandelt der Compiler das C-Programm in ein
Assemblerprogramm
um. Das wiederum wandeln Assembler und Linker in das HEX-File.
Dafür
benötigt der Linker das zum PIC gehörende Linker-Skript (p18xxx.LKR).
Der Programmierer muss also das Quelltext-File schreiben, in das er das Header-File einbindet, und er muss in das Projekt das Linker-Skript des PIC aufnehmen. Device-Header-Files und Linker-Skripte werden für alle in Frage kommenden PIC-Typen mit den Compilern mitgeliefert. Man muss lediglich die richtigen Files aussuchen.
ein
umfangreiches
Projekt
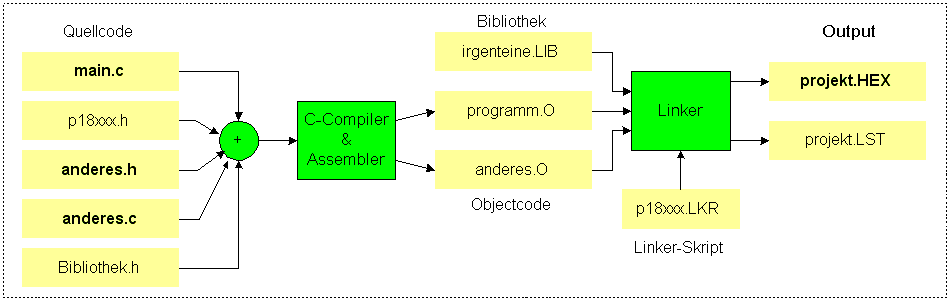
Bei großen Projekten ist es
üblich,
das Programm in mehrere Quelltext-Files (Endung *.c) aufzuteilen. Das
hat
zwei Vorteile
Erklärung
Wenn man einen Teil seines Programms
in das Quelltext-File anderes.c auslagert, dann wird z.B. main.c
Funktionen aus anderes.c benutzen wollen. Ebenso könnte main.c
auf Konstanten, Typen oder Variablen aus anderes.c
zurückgreifen
wollen. All diese Definitionen schreibt man nun nicht direkt in anderes.c
sondern in anderes.h. An den Anfang von anderes.c
fügt
man dann #include anderes.h ein, dadurch steht in anderes.c
an dieser Stelle scheinbar der Inhalt von anderes.h.
Den gleichen include-Befehl setzt man
auch an den Anfang von main.c, und schon kennt main.c
ebenfalls
all die Definitionen, die es braucht, um anderes.c sinnvoll zu
nutzen.
Natürlich kann man die Definition
von Funktionen nicht in das Header-File auslagern, da der C-Quelltext
ja fast nur aus Funktions-Deklarationen besteht. Diese bleiben also
schön im C-File. Die Kopfzeile jeder Deklaration wird aber noch
einmal in das Header-File aufgenommen. Damit "kennt" jedes C-File, in
das das Header-File mit include eingebunden ist, automatisch die
Funktion und ihre Übergabeparameter. Ebenso sollte die
Deklaration von Variablen im C-File verbleiben. In das Header-File
kommt dann eine Kopie der Variablendeklaration mit dem vorgesetzten
Bezeichner extern. Dadurch
werden diese Variablen als globale Variablen allen C-Files "bekannt
gemacht", die das Header-File einbinden.
Diese Aufteilung ist wie gesagt kein Zwang, sondern eine eindringliche Empfehlung. Wer will, kann auch ein beliebig großes Projekt mit nur einem Quelltext-File (main.c) erstellen, dann muss er natürlich kein Header-File schreiben.
Beim Aufruf des Compilers in MPLAB mit Build all werden Quelltext-Files neu compiliert. Wird dagegen der Compiler mit Make gestartet, dann prüft der Compiler zunächst, ob zu einem C-Quelltext-File schon ein Object-File existiert. Wenn er ein Object-File findet, das neuer ist als das Quelltextfile, dann wird dieses Object-File benutzt. Ansonsten wird das Quelltext-File neu compiliert. Make geht deshalb deutlich schneller als Build all.
Bibliotheken
Einige typische Probleme tauchen in vielen
Programmen immer wieder auf, z.B. Warteschleifen oder die
Bedienung
der speziellen IO-Hardware eines PIC. Für solche Probleme
muss
man dann jedes mal die gleichen C-Routinen in den Quelltext schreiben.
Es
wäre aber mühselig, das Rad immer wieder neu zu erfinden.
Deshalb
werden solche hilfreichen Programmschnipsel zu Object-Files assembliert
oder compiliert, und diese kleinen Objectfiles in Bibliotheken
zusammengefasst.
Wenn man dann diese Routine wieder benötigt, dann programmiert man diese nicht neu, sondern verwendet eine fertige Routine aus einer Bibliothek. Solche Bibliotheken sind Files mit der Endung *.LIB'. Zum Lieferumfang der C-Compiler gehören eine ganze Reihe äußerst hilfreicher Bibliotheken. Auch wenn man selber keine Bibliotheken anlegen will, würde nur ein extrem masochistisch veranlagter Programmierer auf die Nutzung der bereits fertigen Bibliotheken verzichten.
Wenn man in einem C-Programm einfach
eine
Funktion aus irgendeiner Bibliothek aufruft, dann wird der Compiler mit
recht schimpfen, denn er kennt diese Funktion ja gar nicht. Wir
müssen
ihn also vorher mit allen Funktionen Vertraut machen, die wir benutzen
wollen. Dazu wird am Quelltextanfang das Header-File der Bibliothek mit
#include
name.h eingebunden ("name" ist natürlich anzupassen).
Eine
Warnung auf den Weg
Meine "Muttersprache" ist Pascal. Beim
Umstieg von Pascal auf C hatte ich
einige Lektionen zu lernen. C ist keine Sprache, die den
Programmierer an die Hand nimmt - im Gegenteil. Es kann sehr leicht
passieren, dass man in C etwas schreibt, das gar nicht den eigenen
Intentionen entspricht, aber vom Compiler anstandslos compiliert wird.
Während andere Sprachen wie Pascal oder gar ADA davon ausgehen,
dass der Programmierer fehlbar ist, und durch ihre Syntax den
Programmierer gewissermaßen überwachen, glaubt der
C-Compiler an die Unfehlbarkeit des Programmierers. Ich möchte das
an einem kleinen Beispiel zeigen. Im folgenden Codeschnipsel teste ich
zunächst, ob die boolsche Variable Fehler den Wert true hat. Wenn ja,
dann
wird eine Funktion gerufen, die z.B. ein Alarmsignal auslöst.
Danach möchte ich den Text "Wir sind im Jahr 2007" ausgeben.
int
wert = 02007;
if (Fehler =
true);
alarm_signal_on();
print("Wir
sind im Jahr %/d\n", wert);
Der Codeschnipsel ist syntaktisch
korrekt, und wird als Teil eines größeren C-Programms
fehlerfrei compiliert. Trotzdem macht er aber absolut nicht das, was
ich will.
weiter
zu
C18
weiter zu C30
weiter zur Einführung in C für
PICs
Autor: sprut
erstellt: 23.03.2006
letzte Änderung: 03.07.2009